DSLExecutor SDK v2
1. Introduction
The DSLExecutor is a comprehensive Python class designed to facilitate the seamless execution of Domain-Specific Language (DSL) workflows. It integrates advanced features such as:
- Multiprocessing-based task execution with enforced CPU, memory, and time resource limits.
- Extensible AddonsManager for registering and invoking webhooks, callbacks, and LLM inference models.
- Human intervention system integration for workflows requiring manual input.
- Persistent state management and output collection for robust workflow tracking and auditing.
This unified interface simplifies initializing, managing, and executing complex DSL workflows reliably and securely.
DSL Executor Architecture
The DSL Executor System is a distributed, thread-managed runtime for orchestrating and executing Domain-Specific Language (DSL) workflows. It combines remote and local execution modes, persistent state tracking, policy-compliant validation, and multi-modal extensions (webhooks, LLMs, human feedback) into a single unified engine. The system is optimized for modularity, observability, and scalable DSL execution in both agent-based and standalone contexts.
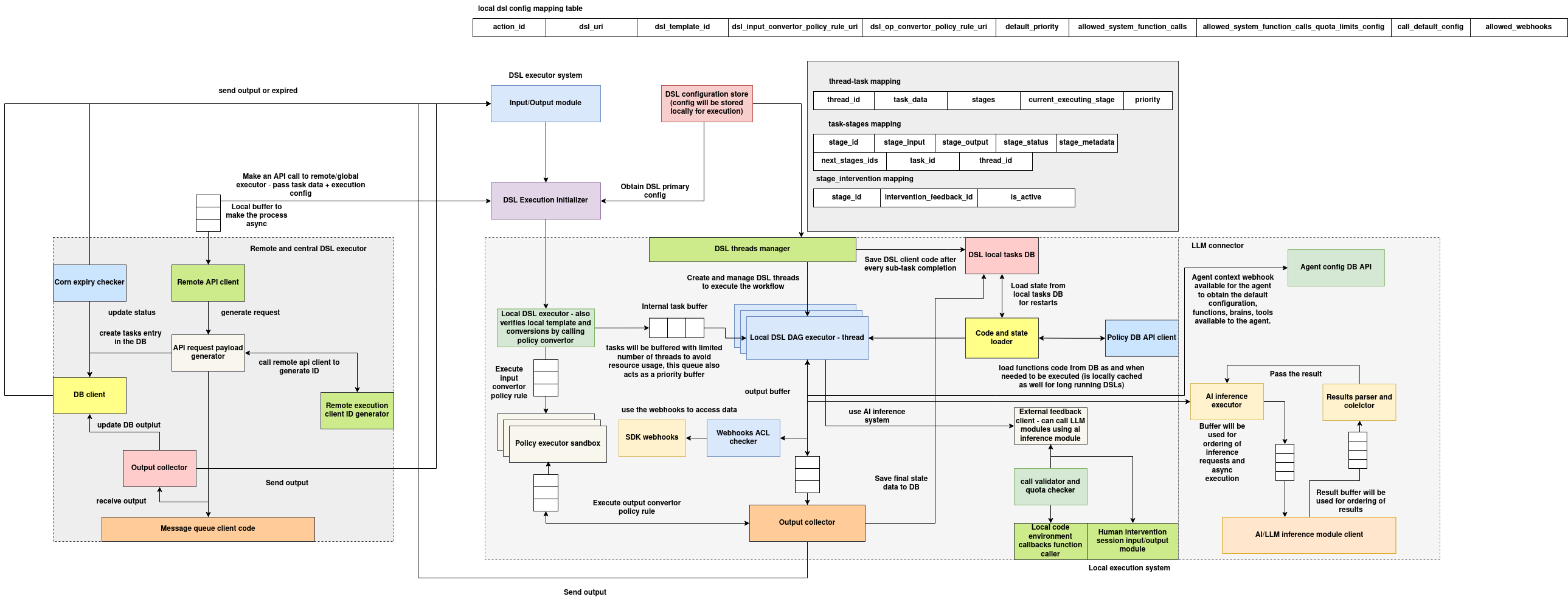
Execution Workflow Overview
The DSL execution begins when a user invokes the DSLExecutor.execute() method with workflow input. Depending on system configuration and DSL metadata, the execution can be local (handled by the DSL DAG thread executor) or remote (delegated to a centralized DSL engine via API).
The system routes execution through these main phases:
-
Input Preparation & Initialization
-
Inputs are received and passed to the
DSL Execution Initializer. - Global configs are loaded from the DSL Configuration Store or central registry.
-
The selected execution path (local or remote) is triggered accordingly.
-
Policy Validation
-
Local execution verifies policies using:
- Input Converter Policy Rule
- Output Converter Policy Rule
- Execution compliance is enforced via a Policy Executor Sandbox using rules defined in the Policy DB.
Local Execution System
When executed locally, the DSL workflow is managed by a multi-threaded executor that ensures controlled resource usage:
- DSL Threads Manager: Initializes and manages the thread pool for DSL tasks. Each thread runs a module in a DAG context.
- Internal Task Buffer: Ensures task queuing and priority-based dispatch.
- Local DSL DAG Executor: Executes modules step-by-step while preserving workflow dependencies.
- Code and State Loader: Loads and caches module code, reads/writes state from DSL Local Tasks DB for crash resilience and restart.
- Output Collector: Gathers outputs, buffers results, and persists to disk or DB.
Modules may invoke:
- SDK Webhooks via the AddonsManager
- LLMs using a pluggable AI inference client
- Human feedback through a remote feedback module
The system also supports:
- ACL validation using Webhooks ACL Checker
- Function execution using Callback Environment
Remote & Central Execution
For systems using centralized DSL management:
- The Remote API Client generates a payload using
API Request Payload Generator. - This payload is sent to a global DSL engine using a Remote Execution Client ID Generator.
- Results are received asynchronously via a Message Queue Client and stored using the DB Client.
- Cron Expiry Checker ensures timeout/retry logic.
- Final outputs are collected and forwarded via the Output Collector.
Addons & Extensions
Execution is extensible using the AddonsManager, which supports:
- Webhook Registration: DSL modules can call external services via REST (with headers, auth).
- Callback Functions: Register custom Python functions usable from within DSL.
- LLM Inference: Plug-in OpenAI/GPT models or internal LLMs using
DSLInferenceAddon.
These addons are invoked from within the workflow using DSL actions or intermediate policies.
AI/LLM Inference Integration
- AI Inference Executor: Buffers and manages inference calls for ordering and concurrency.
- Results Parser and Collector: Aggregates and associates model outputs.
- Agent Config API: Provides runtime context such as tools/functions available to agents.
These systems enable hybrid agent + AI execution inside DSLs.
State Management and Persistence
The WorkflowPersistence layer ensures:
- Durable storage of workflow DSL definitions
- Logging of task/module outputs
- Workflow ID generation and output querying
Used databases may contain:
| Table | Description |
|---|---|
workflow_instances |
Stores DSL definitions + global input |
module_states |
Stores per-task outputs and metadata |
The executor supports:
- Resuming from interrupted state
- Version-safe DSL updates
- Output querying via REST or SDK methods
Thread and Task Mapping
To orchestrate DSL graph execution:
- Each
thread_idis linked to atask_id - Execution stage metadata (
stage_id,stage_input,stage_output) is tracked - Stage-to-stage mappings define transition flows
- Intervention stages enable manual overrides during human feedback workflows
2. Usage Guide
Initialization
from dsl_executor import DSLExecutor
dsl_definition = {
# Your DSL workflow definition as a dictionary
}
# Optional: Initialize AddonsManager and InferenceService with your custom addons
addons_manager = AddonsManager()
inference_service = InferenceService(addons_manager=addons_manager)
executor = DSLExecutor(
dsl_definition=dsl_definition,
addons_manager=addons_manager,
inference_service=inference_service,
max_workers=4,
cpu_limit=60, # CPU seconds per task
mem_limit=512 * 1024 * 1024, # 512 MB memory per task
time_limit=300, # Total workflow execution time limit in seconds
human_intervention_api_url="http://your-human-intervention-api",
human_intervention_subject_id="your_subject_id"
)
Executing a Workflow
input_data = {
# Input parameters for your workflow
}
result = executor.execute(input_data)
print("Workflow output:", result)
Retrieving Outputs
# Get output of a specific task/module
task_output = executor.get_task_output("module_key")
# Get aggregated workflow output
workflow_output = executor.get_workflow_output()
Persisting Outputs
executor.persist_outputs()
Cleanup
executor.close()
3. Methods
| Method | Description |
|---|---|
__init__(...) |
Initializes the DSLExecutor with DSL definition, addons, resource limits, and workflow ID. |
execute(input_data) |
Executes the DSL workflow with provided input data; returns the final output dictionary. |
get_task_output(module_key) |
Retrieves the output of a specific task/module by its key. |
get_workflow_output() |
Retrieves aggregated outputs for the entire workflow. |
persist_outputs() |
Persists collected outputs to the configured storage backend. |
close() |
Gracefully shuts down resources, worker processes, and persistence connections. |
4. Addons Manager
The AddonsManager allows registering and managing various addons that DSL workflows can invoke during execution.
Registering Callbacks
from addons_manager import DSLCallback
def my_callback(data):
# Your callback logic
return "callback result"
callback = DSLCallback(name="my_callback", callback_fn=my_callback)
addons_manager.register_callback(callback)
Registering Webhooks
from addons_manager import DSLWebhook
from default_webhook import DefaultWebhook
webhook_client = DefaultWebhook(
url="https://example.com/api",
method="POST",
headers={"Authorization": "Bearer token"}
)
webhook = DSLWebhook(name="my_webhook", client=webhook_client)
addons_manager.register_webhook(webhook)
Registering LLM Models
from addons_manager import DSLInferenceAddon
from openai_inference_api import OpenAIInferenceAPI
llm_api = OpenAIInferenceAPI(api_key="your_api_key")
llm_addon = DSLInferenceAddon(name="openai_gpt4o", inference_api=llm_api)
addons_manager.register_inference_addon(llm_addon)
5. Resource Limits
DSLExecutor enforces resource limits per task to ensure stability and fairness:
- CPU Time Limit: Maximum CPU seconds a task can consume.
- Memory Limit: Maximum virtual memory (address space) a task can allocate.
- Execution Time Limit: Maximum wall-clock time for the entire workflow execution.
These limits are applied at the OS level using Python's resource module within worker processes.
Configuration Example:
executor = DSLExecutor(
dsl_definition=dsl_definition,
cpu_limit=60, # 60 seconds CPU time per task
mem_limit=512 * 1024 * 1024, # 512 MB memory per task
time_limit=300 # 5 minutes total execution time
)
6. State Saving
Persistence Layer
The executor uses a WorkflowPersistence component (pluggable) to save:
- Workflow instance definitions and global parameters.
- Module/task execution outputs and states.
This enables workflow resumption, auditing, and debugging.
Database Schema (Example)
| Table Name | Description | Key Columns |
|---|---|---|
workflow_instances |
Stores workflow DSL and global params | workflow_id, dsl_definition |
module_states |
Stores individual module outputs | workflow_id, module_key, output |
Output Collector
- Collects outputs from each module during execution.
- Aggregates outputs for the entire workflow.
- Supports persisting outputs to storage (e.g., JSON files, DB).
- Provides retrieval APIs for downstream consumption.